At Etsy, we have a nice, clean, streamlined build process. We have a command for setting up RAID, and another for OS installation. OS installation comes with automagic for LDAP, Chef roles, etc.
We came across an odd scenario today when a co-worker was building a box that gave the following error:
Traceback (most recent call first):
File “/usr/lib/anaconda/storage/partitioning.py”, line 1066, in allocatePartitions
disklabel = disklabels[_disk.path]
File “/usr/lib/anaconda/storage/partitioning.py”, line 977, in doPartitioning
allocatePartitions(storage, disks, partitions, free)
File “/usr/lib/anaconda/storage/partitioning.py”, line 274, in doAutoPartition
exclusiveDisks=exclusiveDisks)
File “/usr/lib/anaconda/dispatch.py”, line 210, in moveStep
rc = stepFunc(self.anaconda)
File “/usr/lib/anaconda/dispatch.py”, line 126, in gotoNext
self.moveStep()
File “/usr/lib/anaconda/dispatch.py”, line 233, in currentStep
self.gotoNext()
File “/usr/lib/anaconda/text.py”, line 602, in run
(step, instance) = anaconda.dispatch.currentStep()
File “/usr/bin/anaconda”, line 1131, in <module>
anaconda.intf.run(anaconda)
KeyError: ‘/dev/sda’
It suggests a problem with setting up partitions on /dev/sda, where we would put the boot partition. I knew it
seemed familiar but I couldn’t recall the solution, and Google, while usually wonderful, got us to a Red Hat Support article behind a paywall. A few other results suggested the boot order was incorrect. The OS was thinking the drives were out of order. Being a Dell box, I checked the virtual drive order, which in my experience always has matched the boot order:
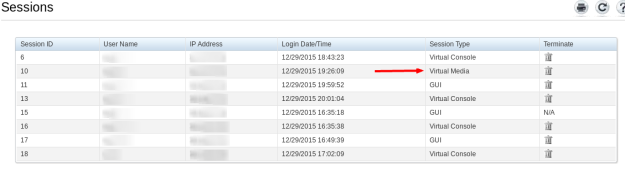
After the anaconda failure, I went into another terminal to a prompt and checked /proc/partitions. Sure enough, we started at sdb, not sda. Then it hit me. There were 4 people viewing the console in iDRAC, so what if someone else had mounted a virtual disk and that was /dev/sda? Sure enough:
Deleting the virtual media session, rebooting and starting the OS install again proved out everything worked fine.
The bonus humor here is that this isn’t the first time we’ve run into this. Hopefully after posting this, Google will index this page and point us to the answer a bit quicker next time.